第三方推理框架迁移到modelarts standard推理自定义引擎-九游平台
背景说明
modelarts支持第三方的推理框架在modelarts上部署,本文以tfserving框架、triton框架为例,介绍如何迁移到推理自定义引擎。
- tensorflow serving是一个灵活、高性能的机器学习模型部署系统,提供模型版本管理、服务回滚等能力。通过配置模型路径、模型端口、模型名称等参数,原生tfserving镜像可以快速启动提供服务,并支持grpc和http restful api的访问方式。
- triton是一个高性能推理服务框架,提供http/grpc等多种服务协议,支持tensorflow、tensorrt、pytorch、onnxruntime等多种推理引擎后端,并且支持多模型并发、动态batch等功能,能够提高gpu的使用率,改善推理服务的性能。
当从第三方推理框架迁移到使用modelarts推理的模型管理和服务管理时,需要对原生第三方推理框架镜像的构建方式做一定的改造,以使用modelarts推理平台的模型版本管理能力和动态加载模型的部署能力。本案例将指导用户完成原生第三方推理框架镜像到modelarts推理自定义引擎的改造。自定义引擎的镜像制作完成后,即可以通过模型导入对模型版本进行管理,并基于模型进行部署和管理服务。
适配和改造的主要工作项如下:

针对不同框架的镜像,可能还需要做额外的适配工作,具体差异请见对应框架的操作步骤。
tfserving框架迁移操作步骤
- 增加用户ma-user。
基于原生"tensorflow/serving:2.8.0"镜像构建,镜像中100的用户组默认已存在,dockerfile中执行如下命令增加用户ma-user。
run useradd -d /home/ma-user -m -u 1000 -g 100 -s /bin/bash ma-user
- 通过增加nginx代理,支持https协议。
协议转换为https之后,对外暴露的端口从tfserving的8501变为8080。
- dockerfile中执行如下命令完成nginx的安装和配置。
run apt-get update && apt-get -y --no-install-recommends install nginx && apt-get clean run mkdir /home/mind && \ mkdir -p /etc/nginx/keys && \ mkfifo /etc/nginx/keys/fifo && \ chown -r ma-user:100 /home/mind && \ rm -rf /etc/nginx/conf.d/default.conf && \ chown -r ma-user:100 /etc/nginx/ && \ chown -r ma-user:100 /var/log/nginx && \ chown -r ma-user:100 /var/lib/nginx && \ sed -i "s#/var/run/nginx.pid#/home/ma-user/nginx.pid#g" /etc/init.d/nginx add nginx /etc/nginx add run.sh /home/mind/ entrypoint [] cmd /bin/bash /home/mind/run.sh - 准备nginx目录如下:
nginx ├──nginx.conf └──conf.d ├── modelarts-model-server.conf - 准备nginx.conf文件内容如下:
user ma-user 100; worker_processes 2; pid /home/ma-user/nginx.pid; include /etc/nginx/modules-enabled/*.conf; events { worker_connections 768; } http { ## # basic settings ## sendfile on; tcp_nopush on; tcp_nodelay on; types_hash_max_size 2048; fastcgi_hide_header x-powered-by; port_in_redirect off; server_tokens off; client_body_timeout 65s; client_header_timeout 65s; keepalive_timeout 65s; send_timeout 65s; # server_names_hash_bucket_size 64; # server_name_in_redirect off; include /etc/nginx/mime.types; default_type application/octet-stream; ## # ssl settings ## ssl_protocols tlsv1.2; ssl_prefer_server_ciphers on; ssl_ciphers ecdhe-rsa-aes128-gcm-sha256:ecdhe-ecdsa-aes128-gcm-sha256; ## # logging settings ## access_log /var/log/nginx/access.log; error_log /var/log/nginx/error.log; ## # gzip settings ## gzip on; ## # virtual host configs ## include /etc/nginx/conf.d/modelarts-model-server.conf; } - 准备modelarts-model-server.conf配置文件内容如下:
server { client_max_body_size 15m; large_client_header_buffers 4 64k; client_header_buffer_size 1k; client_body_buffer_size 16k; ssl_certificate /etc/nginx/ssl/server/server.crt; ssl_password_file /etc/nginx/keys/fifo; ssl_certificate_key /etc/nginx/ssl/server/server.key; # setting for mutual ssl with client ## # header settings ## add_header x-xss-protection "1; mode=block"; add_header x-frame-options sameorigin; add_header x-content-type-options nosniff; add_header strict-transport-security "max-age=31536000; includesubdomains;"; add_header content-security-policy "default-src 'self'"; add_header cache-control "max-age=0, no-cache, no-store, must-revalidate"; add_header pragma "no-cache"; add_header expires "-1"; server_tokens off; port_in_redirect off; fastcgi_hide_header x-powered-by; ssl_session_timeout 2m; ## # ssl settings ## ssl_protocols tlsv1.2; ssl_prefer_server_ciphers on; ssl_ciphers ecdhe-rsa-aes128-gcm-sha256:ecdhe-ecdsa-aes128-gcm-sha256; listen 0.0.0.0:8080 ssl; error_page 502 503 /503.html; location /503.html { return 503 '{"error_code": "modelarts.4503","error_msg": "failed to connect to backend service, please confirm your service is connectable. "}'; } location / { # limit_req zone=mylimit; # limit_req_status 429; proxy_pass http://127.0.0.1:8501; } } - 准备启动脚本。

启动前先创建ssl证书,然后启动tfserving的启动脚本。
启动脚本run.sh示例代码如下:
#!/bin/bash mkdir -p /etc/nginx/ssl/server && cd /etc/nginx/ssl/server ciphertext=$(openssl rand -base64 32) openssl genrsa -aes256 -passout pass:"${ciphertext}" -out server.key 2048 openssl rsa -in server.key -passin pass:"${ciphertext}" -pubout -out rsa_public.key openssl req -new -key server.key -passin pass:"${ciphertext}" -out server.csr -subj "/c=cn/st=gd/l=sz/o=huawei/ou=ops/cn=*.huawei.com" openssl genrsa -out ca.key 2048 openssl req -new -x509 -days 3650 -key ca.key -out ca-crt.pem -subj "/c=cn/st=gd/l=sz/o=huawei/ou=dev/cn=ca" openssl x509 -req -days 3650 -in server.csr -ca ca-crt.pem -cakey ca.key -cacreateserial -out server.crt service nginx start & echo ${ciphertext} > /etc/nginx/keys/fifo unset ciphertext sh /usr/bin/tf_serving_entrypoint.sh
- dockerfile中执行如下命令完成nginx的安装和配置。
- 修改模型默认路径,支持modelarts推理模型动态加载。
dockerfile中执行如下命令修改默认的模型路径。
env model_base_path /home/mind env model_name model
完整的dockerfile参考:
from tensorflow/serving:2.8.0
run useradd -d /home/ma-user -m -u 1000 -g 100 -s /bin/bash ma-user
run apt-get update && apt-get -y --no-install-recommends install nginx && apt-get clean
run mkdir /home/mind && \
mkdir -p /etc/nginx/keys && \
mkfifo /etc/nginx/keys/fifo && \
chown -r ma-user:100 /home/mind && \
rm -rf /etc/nginx/conf.d/default.conf && \
chown -r ma-user:100 /etc/nginx/ && \
chown -r ma-user:100 /var/log/nginx && \
chown -r ma-user:100 /var/lib/nginx && \
sed -i "s#/var/run/nginx.pid#/home/ma-user/nginx.pid#g" /etc/init.d/nginx
add nginx /etc/nginx
add run.sh /home/mind/
env model_base_path /home/mind
env model_name model
entrypoint []
cmd /bin/bash /home/mind/run.sh
triton框架迁移操作步骤
本教程基于nvidia官方提供的nvcr.io/nvidia/tritonserver:23.03-py3镜像进行适配,使用开源大模型llama7b进行推理任务。
- 增加用户ma-user。
triton镜像中默认已存在id为1000的triton-server用户,需先修改triton-server用户名id后再增加用户ma-user,dockerfile中执行如下命令。
run usermod -u 1001 triton-server && useradd -d /home/ma-user -m -u 1000 -g 100 -s /bin/bash ma-user
- 通过增加nginx代理,支持https协议。
- dockerfile中执行如下命令完成nginx的安装和配置。
run apt-get update && apt-get -y --no-install-recommends install nginx && apt-get clean && \ mkdir /home/mind && \ mkdir -p /etc/nginx/keys && \ mkfifo /etc/nginx/keys/fifo && \ chown -r ma-user:100 /home/mind && \ rm -rf /etc/nginx/conf.d/default.conf && \ chown -r ma-user:100 /etc/nginx/ && \ chown -r ma-user:100 /var/log/nginx && \ chown -r ma-user:100 /var/lib/nginx && \ sed -i "s#/var/run/nginx.pid#/home/ma-user/nginx.pid#g" /etc/init.d/nginx - 准备nginx目录如下:
nginx ├──nginx.conf └──conf.d ├── modelarts-model-server.conf - 准备nginx.conf文件内容如下:
user ma-user 100; worker_processes 2; pid /home/ma-user/nginx.pid; include /etc/nginx/modules-enabled/*.conf; events { worker_connections 768; } http { ## # basic settings ## sendfile on; tcp_nopush on; tcp_nodelay on; types_hash_max_size 2048; fastcgi_hide_header x-powered-by; port_in_redirect off; server_tokens off; client_body_timeout 65s; client_header_timeout 65s; keepalive_timeout 65s; send_timeout 65s; # server_names_hash_bucket_size 64; # server_name_in_redirect off; include /etc/nginx/mime.types; default_type application/octet-stream; ## # ssl settings ## ssl_protocols tlsv1.2; ssl_prefer_server_ciphers on; ssl_ciphers ecdhe-rsa-aes128-gcm-sha256:ecdhe-ecdsa-aes128-gcm-sha256; ## # logging settings ## access_log /var/log/nginx/access.log; error_log /var/log/nginx/error.log; ## # gzip settings ## gzip on; ## # virtual host configs ## include /etc/nginx/conf.d/modelarts-model-server.conf; } - 准备modelarts-model-server.conf配置文件内容如下:
server { client_max_body_size 15m; large_client_header_buffers 4 64k; client_header_buffer_size 1k; client_body_buffer_size 16k; ssl_certificate /etc/nginx/ssl/server/server.crt; ssl_password_file /etc/nginx/keys/fifo; ssl_certificate_key /etc/nginx/ssl/server/server.key; # setting for mutual ssl with client ## # header settings ## add_header x-xss-protection "1; mode=block"; add_header x-frame-options sameorigin; add_header x-content-type-options nosniff; add_header strict-transport-security "max-age=31536000; includesubdomains;"; add_header content-security-policy "default-src 'self'"; add_header cache-control "max-age=0, no-cache, no-store, must-revalidate"; add_header pragma "no-cache"; add_header expires "-1"; server_tokens off; port_in_redirect off; fastcgi_hide_header x-powered-by; ssl_session_timeout 2m; ## # ssl settings ## ssl_protocols tlsv1.2; ssl_prefer_server_ciphers on; ssl_ciphers ecdhe-rsa-aes128-gcm-sha256:ecdhe-ecdsa-aes128-gcm-sha256; listen 0.0.0.0:8080 ssl; error_page 502 503 /503.html; location /503.html { return 503 '{"error_code": "modelarts.4503","error_msg": "failed to connect to backend service, please confirm your service is connectable. "}'; } location / { # limit_req zone=mylimit; # limit_req_status 429; proxy_pass http://127.0.0.1:8000; } } - 准备启动脚本run.sh。
启动前先创建ssl证书,然后启动triton的启动脚本。
#!/bin/bash mkdir -p /etc/nginx/ssl/server && cd /etc/nginx/ssl/server ciphertext=$(openssl rand -base64 32) openssl genrsa -aes256 -passout pass:"${ciphertext}" -out server.key 2048 openssl rsa -in server.key -passin pass:"${ciphertext}" -pubout -out rsa_public.key openssl req -new -key server.key -passin pass:"${ciphertext}" -out server.csr -subj "/c=cn/st=gd/l=sz/o=huawei/ou=ops/cn=*.huawei.com" openssl genrsa -out ca.key 2048 openssl req -new -x509 -days 3650 -key ca.key -out ca-crt.pem -subj "/c=cn/st=gd/l=sz/o=huawei/ou=dev/cn=ca" openssl x509 -req -days 3650 -in server.csr -ca ca-crt.pem -cakey ca.key -cacreateserial -out server.crt service nginx start & echo ${ciphertext} > /etc/nginx/keys/fifo unset ciphertext bash /home/mind/model/triton_serving.sh
- dockerfile中执行如下命令完成nginx的安装和配置。
- 编译安装tensorrtllm_backend。
- dockerfile中执行如下命令获取tensorrtllm_backend源码,安装tensorrt、cmake和pytorch等相关依赖,并进行编译安装。
# get tensortllm_backend source code workdir /opt/tritonserver run apt-get install -y --no-install-recommends rapidjson-dev python-is-python3 git-lfs && \ git config --global http.sslverify false && \ git config --global http.postbuffer 1048576000 && \ git clone -b v0.5.0 https://github.com/triton-inference-server/tensorrtllm_backend.git --depth 1 && \ cd tensorrtllm_backend && git lfs install && \ git config submodule.tensorrt_llm.url https://github.com/nvidia/tensorrt-llm.git && \ git submodule update --init --recursive --depth 1 && \ pip3 install -r requirements.txt # build tensorrtllm_backend workdir /opt/tritonserver/tensorrtllm_backend/tensorrt_llm run sed -i "s/wget/wget --no-check-certificate/g" docker/common/install_tensorrt.sh && \ bash docker/common/install_tensorrt.sh && \ export ld_library_path=/usr/local/tensorrt/lib:${ld_library_path} && \ sed -i "s/wget/wget --no-check-certificate/g" docker/common/install_cmake.sh && \ bash docker/common/install_cmake.sh && \ export path=/usr/local/cmake/bin:$path && \ bash docker/common/install_pytorch.sh pypi && \ python3 ./scripts/build_wheel.py --trt_root /usr/local/tensorrt && \ pip install ./build/tensorrt_llm-0.5.0-py3-none-any.whl && \ rm -f ./build/tensorrt_llm-0.5.0-py3-none-any.whl && \ cd ../inflight_batcher_llm && bash scripts/build.sh && \ mkdir /opt/tritonserver/backends/tensorrtllm && \ cp ./build/libtriton_tensorrtllm.so /opt/tritonserver/backends/tensorrtllm/ && \ chown -r ma-user:100 /opt/tritonserver - 准备triton serving的启动脚本triton_serving.sh,llama模型的参考样例如下:
model_name=llama_7b model_dir=/home/mind/model/${model_name} output_dir=/tmp/llama/7b/trt_engines/fp16/1-gpu/ max_batch_size=1 export ld_library_path=/usr/local/tensorrt/lib:${ld_library_path} # build tensorrt_llm engine cd /opt/tritonserver/tensorrtllm_backend/tensorrt_llm/examples/llama python build.py --model_dir ${model_dir} \ --dtype float16 \ --remove_input_padding \ --use_gpt_attention_plugin float16 \ --enable_context_fmha \ --use_weight_only \ --use_gemm_plugin float16 \ --output_dir ${output_dir} \ --paged_kv_cache \ --max_batch_size ${max_batch_size} # set config parameters cd /opt/tritonserver/tensorrtllm_backend mkdir triton_model_repo cp all_models/inflight_batcher_llm/* triton_model_repo/ -r python3 tools/fill_template.py -i triton_model_repo/preprocessing/config.pbtxt tokenizer_dir:${model_dir},tokenizer_type:llama,triton_max_batch_size:${max_batch_size},preprocessing_instance_count:1 python3 tools/fill_template.py -i triton_model_repo/postprocessing/config.pbtxt tokenizer_dir:${model_dir},tokenizer_type:llama,triton_max_batch_size:${max_batch_size},postprocessing_instance_count:1 python3 tools/fill_template.py -i triton_model_repo/ensemble/config.pbtxt triton_max_batch_size:${max_batch_size} python3 tools/fill_template.py -i triton_model_repo/tensorrt_llm/config.pbtxt triton_max_batch_size:${max_batch_size},decoupled_mode:false,max_beam_width:1,engine_dir:${output_dir},max_tokens_in_paged_kv_cache:2560,max_attention_window_size:2560,kv_cache_free_gpu_mem_fraction:0.5,exclude_input_in_output:true,enable_kv_cache_reuse:false,batching_strategy:v1,max_queue_delay_microseconds:600 # launch tritonserver python3 scripts/launch_triton_server.py --world_size 1 --model_repo=triton_model_repo/ while true; do sleep 10000; done部分参数说明:
- model_name:huggingface格式模型权重文件所在obs文件夹名称。
- output_dir:通过tensorrt-llm转换后的模型文件在容器中的路径。
完整的dockerfile如下:
from nvcr.io/nvidia/tritonserver:23.03-py3 # add ma-user and install nginx run usermod -u 1001 triton-server && useradd -d /home/ma-user -m -u 1000 -g 100 -s /bin/bash ma-user && \ apt-get update && apt-get -y --no-install-recommends install nginx && apt-get clean && \ mkdir /home/mind && \ mkdir -p /etc/nginx/keys && \ mkfifo /etc/nginx/keys/fifo && \ chown -r ma-user:100 /home/mind && \ rm -rf /etc/nginx/conf.d/default.conf && \ chown -r ma-user:100 /etc/nginx/ && \ chown -r ma-user:100 /var/log/nginx && \ chown -r ma-user:100 /var/lib/nginx && \ sed -i "s#/var/run/nginx.pid#/home/ma-user/nginx.pid#g" /etc/init.d/nginx # get tensortllm_backend source code workdir /opt/tritonserver run apt-get install -y --no-install-recommends rapidjson-dev python-is-python3 git-lfs && \ git config --global http.sslverify false && \ git config --global http.postbuffer 1048576000 && \ git clone -b v0.5.0 https://github.com/triton-inference-server/tensorrtllm_backend.git --depth 1 && \ cd tensorrtllm_backend && git lfs install && \ git config submodule.tensorrt_llm.url https://github.com/nvidia/tensorrt-llm.git && \ git submodule update --init --recursive --depth 1 && \ pip3 install -r requirements.txt # build tensorrtllm_backend workdir /opt/tritonserver/tensorrtllm_backend/tensorrt_llm run sed -i "s/wget/wget --no-check-certificate/g" docker/common/install_tensorrt.sh && \ bash docker/common/install_tensorrt.sh && \ export ld_library_path=/usr/local/tensorrt/lib:${ld_library_path} && \ sed -i "s/wget/wget --no-check-certificate/g" docker/common/install_cmake.sh && \ bash docker/common/install_cmake.sh && \ export path=/usr/local/cmake/bin:$path && \ bash docker/common/install_pytorch.sh pypi && \ python3 ./scripts/build_wheel.py --trt_root /usr/local/tensorrt && \ pip install ./build/tensorrt_llm-0.5.0-py3-none-any.whl && \ rm -f ./build/tensorrt_llm-0.5.0-py3-none-any.whl && \ cd ../inflight_batcher_llm && bash scripts/build.sh && \ mkdir /opt/tritonserver/backends/tensorrtllm && \ cp ./build/libtriton_tensorrtllm.so /opt/tritonserver/backends/tensorrtllm/ && \ chown -r ma-user:100 /opt/tritonserver add nginx /etc/nginx add run.sh /home/mind/ cmd /bin/bash /home/mind/run.sh完成镜像构建后,将镜像注册至华为云容器镜像服务swr中,用于后续在modelarts上部署推理服务。
- dockerfile中执行如下命令获取tensorrtllm_backend源码,安装tensorrt、cmake和pytorch等相关依赖,并进行编译安装。
- 使用适配后的镜像在modelarts部署在线推理服务。
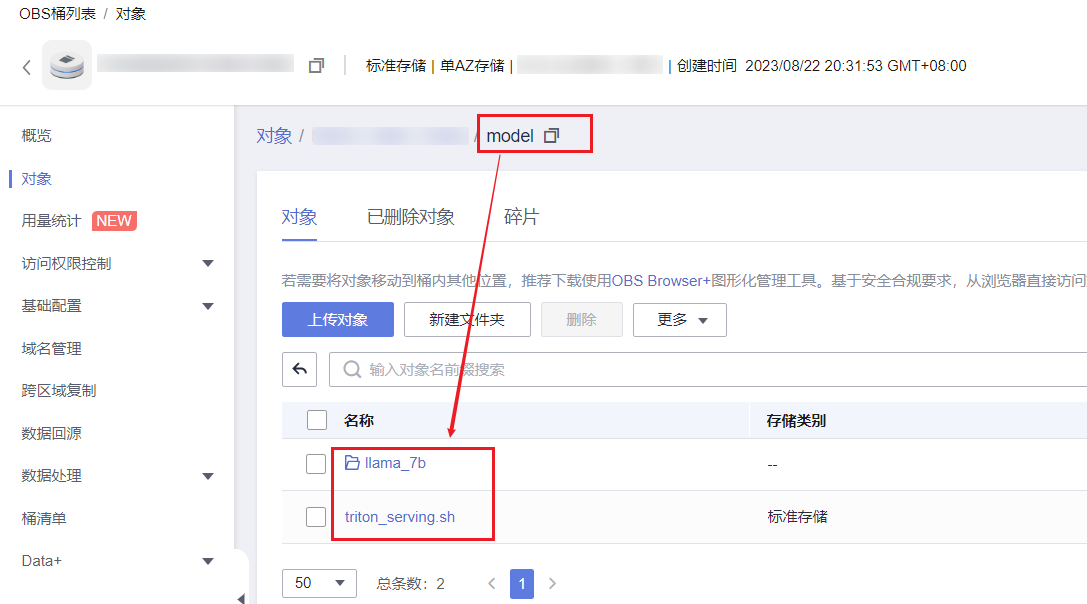
- 在obs中创建model目录,并将triton_serving.sh文件和llama_7b文件夹上传至model目录下,如下图所示。
图2 上传至model目录
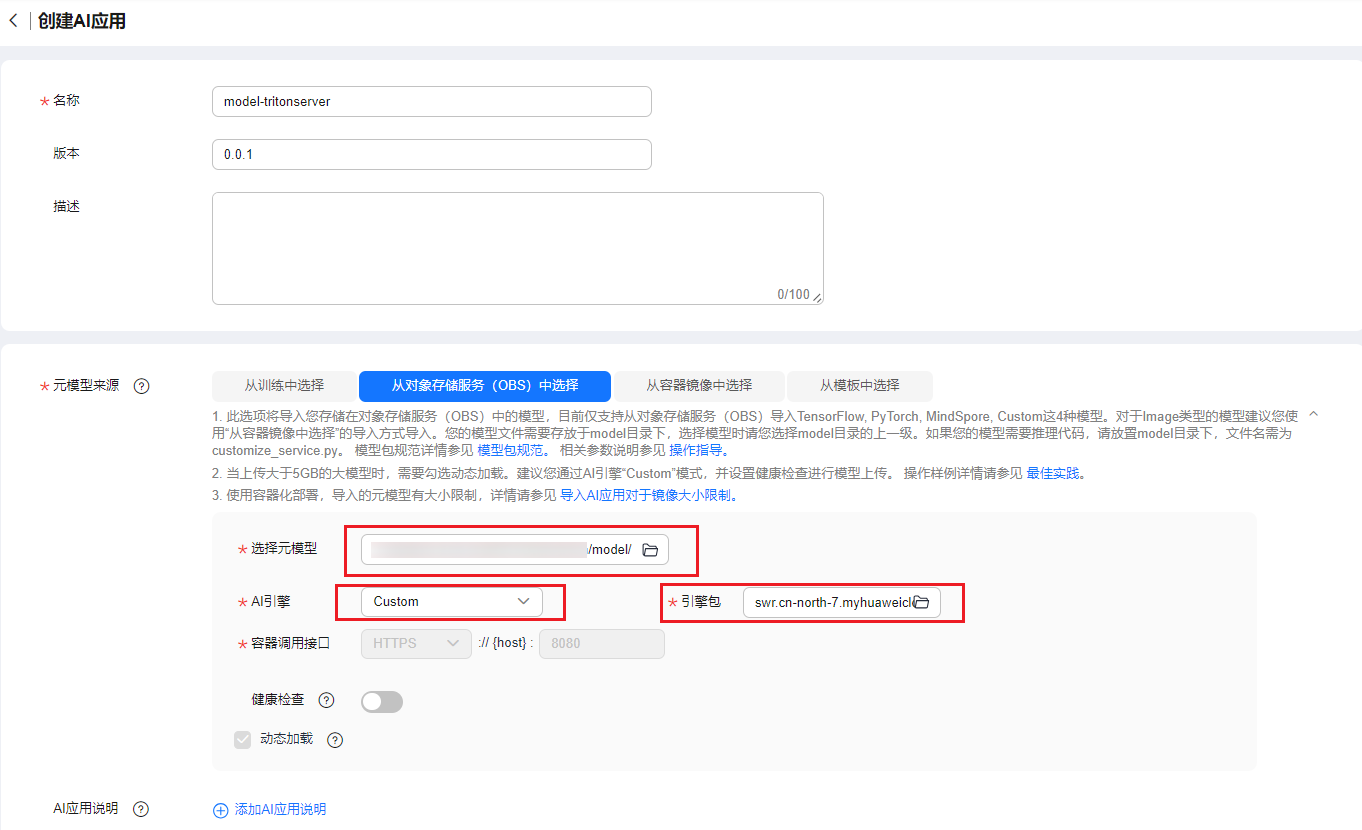
- 创建模型,源模型来源选择“从对象存储服务(obs)中选择”,元模型选择至model目录,ai引擎选择custom,引擎包选择步骤3构建的镜像。
图3 创建模型
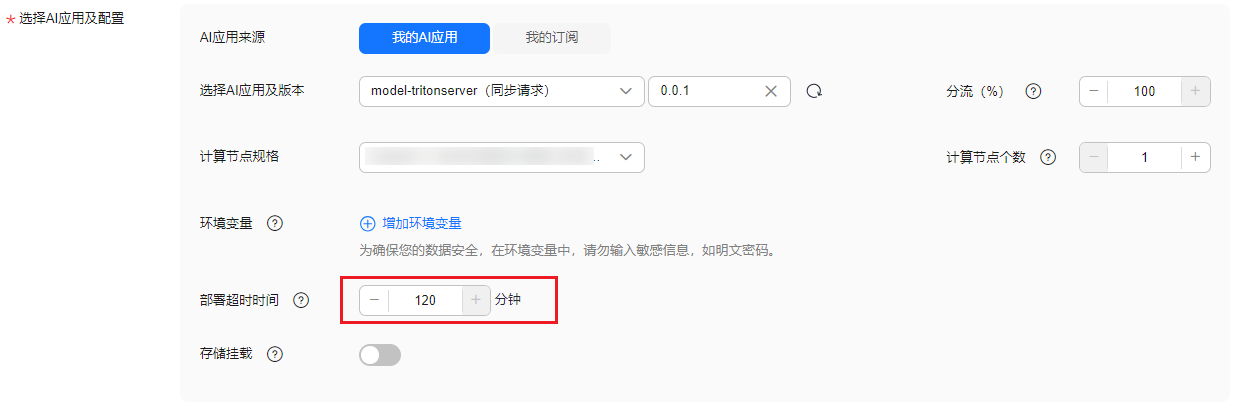
- 将创建的模型部署为在线服务,大模型加载启动的时间一般大于普通的模型创建的服务,请配置合理的“部署超时时间”,避免尚未启动完成被认为超时而导致部署失败。
图4 部署为在线服务
- 调用在线服务进行大模型推理,请求路径填写/v2/models/ensemble/infer,调用样例如下:
{ "inputs": [ { "name": "text_input", "shape": [1, 1], "datatype": "bytes", "data": ["what is machine learning"] }, { "name": "max_tokens", "shape": [1, 1], "datatype": "uint32", "data": [64] }, { "name": "bad_words", "shape": [1, 1], "datatype": "bytes", "data": [""] }, { "name": "stop_words", "shape": [1, 1], "datatype": "bytes", "data": [""] }, { "name": "pad_id", "shape": [1, 1], "datatype": "uint32", "data": [2] }, { "name": "end_id", "shape": [1, 1], "datatype": "uint32", "data": [2] } ], "outputs": [ { "name": "text_output" } ] }
- "inputs"中"name"为"text_input"的元素代表输入,"data"为具体输入语句,本示例中为"what is machine learning"。
- "inputs"中"name"为"max_tokens"的元素代表输出最大tokens数,"data"为具体数值,本示例中为64。
图5 调用在线服务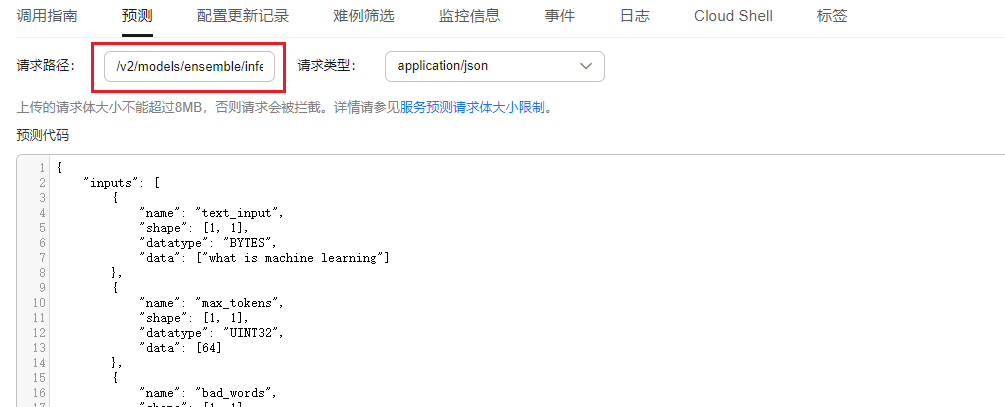
- 在obs中创建model目录,并将triton_serving.sh文件和llama_7b文件夹上传至model目录下,如下图所示。
相关文档
意见反馈
文档内容是否对您有帮助?
如您有其它疑问,您也可以通过华为云社区问答频道来与我们联系探讨




